
Anonymisation : erreurs courantes et mesures préconisées
L’anonymisation est le seul traitement permettant de faire sortir les données du champ d’application du RGPD. Cependant, elle est source de nombreuses erreurs et incompréhensions, essentiellement dues à une méconnaissance des risques dits de ré-identification, mais également, à une ignorance des mesures réglementaires encadrant ce traitement de données à caractère personnel.
L’anonymisation fait sortir les données du champ d’application du RGPD. Ainsi, aucun principe du RGPD ne s’applique aux données anonymisées, ce qui offre plus de flexibilité aux entreprises pour le développement de services innovants et l’amélioration de services existants. Ainsi, certains traitements s’y prêtent tout particulièrement parmi lesquels : le développement de modèles d’intelligence artificiel, l’utilisation de données de production pour faire du test d’applications, la conservation de données au-delà de la durée légale de conservation, la recherche en santé, l’open data …
Cependant, pour bénéficier de tous ces avantages, il est nécessaire que l’anonymisation soit réalisée de manière conforme. Que signifie donc « anonymisation conforme » ?
Afin de répondre à cette question, le groupe de travail 29 (G29) – actuel CEPD -, qui regroupe l’ensemble des autorités de protection de données Européennes (dont la CNIL), publie en 2014 un avis sur les techniques d’anonymisation. Dans cet avis, le G29 identifie plusieurs critères à la fois techniques et réglementaires, qu’il est nécessaire de remplir pour prétendre à une anonymisation conforme. Ces critères visent à s’assurer que le processus d’anonymisation permet de réduire de manière suffisante les risques de ré-identification.
Cependant, bien que cet avis soit considéré par la CNIL comme la principale référence en matière d’anonymisation, il reste encore très peu connu de la plupart des organismes traitant des données à caractère personnel. Par ailleurs, ceux qui en ont connaissance ne détiennent pas nécessairement l’expertise requise pour la mise en œuvre des mesures techniques qui y sont recommandées. En effet, l’avis précise que pour qu’une méthode d’anonymisation soit conforme, elle doit respecter entre autres, des critères techniques que sont : l’individualisation, la corrélation et l’inférence.
Ces limites sont la principale source d’erreurs et de confusions en matière d’anonymisation.
- Les erreurs relatives à l’anonymisation
Les erreurs relatives à l’anonymisation peuvent être décliner selon 3 axes : réglementaire, organisationnel et technique.
a. Sur le plan réglementaire
- Ne pas considérer l’anonymisation comme un traitement de données à caractère personnel : en effet, l’anonymisation est un traitement de données à caractère personnel car, si en sortie d’une anonymisation les données sont anonymisées et hors de portée du RGPD ; en entrée d’une anonymisation, il s’agit bien de données personnelles, encadrées par le RGPD. Si de plus, l’anonymisation est éligible à une AIPD (ex : utilisation de données de santé et usage de technologies innovantes), cela pourrait conduire à des sanctions importantes (jusqu’à 2% du CA, ou 10 millions d’euros), prévues par le RGPD en cas d’absence d’AIPD
- Une base légale inappropriée : l’anonymisation étant un traitement, elle nécessite une base légale appropriée (ex : consentement, intérêt légitime, obligation légale). L’une des bases légales les plus utilisées pour l’anonymisation est « l’intérêt légitime ». Cependant, cette base légale nécessite une balance des intérêts bien menée, ce qui n’est pas souvent le cas car elle est malheureusement souvent biaisée ou absente
- Une absence d’information des personnes : l’information des personnes, même dans le cadre d’un traitement visant l’anonymisation, est nécessaire. Il est donc nécessaire de l’anticiper et de la faire au moment de la collecte, car après, il peut être trop tard (ex : information des personnes dont les données se trouvent dans un Data Lake)
- Penser qu’il est nécessaire de supprimer les données d’origine : contrairement à une idée répandue, il n’est pas nécessaire de supprimer les données d’origine ayant servies de source à l’anonymisation. En effet, si ces données sont utilisées dans le cadre d’un traitement conforme au RGPD, elles peuvent être conservées
b. Sur le plan organisationnel
- Ne pas anticiper les actions d’anonymisation : ceci est particulièrement utile dans le cas d’une anonymisation pour le respect des durées de conservation ou du droit à l’oubli. En effet, ces traitements se font au fil de l’eau, selon un calendrier prédéfini. Si un processus d’anonymisation n’est pas prévu en amont, il sera difficile d’y remédier
- Ne pas prévoir des clauses contractuelles spécifiques : des clauses contractuelles spécifiques doivent être définies, notamment dans le cadre d’échange de données avec des prestataires externes. Elles doivent prévoir entre autres, un engagement des prestataires et sous-traitants à ne pas essayer de ré-identifier les personnes concernées
- Ne pas centraliser le processus d’anonymisation : le processus d’anonymisation doit être centralisé, notamment pour permettre de garantir la cohérence de l’anonymisation entre différents environnements/cas d’usage, et de maitriser la purge et la sécurité des données
- Ne pas prévoir des mesures de sécurité supplémentaires : en effet, l’objectif visé par l’anonymisation est de réduire les risques de ré-identification, et il est toujours utile de prévoir des mesures de sécurité supplémentaires (ex : contrôle des accès, chiffrement des données …). Cela est particulièrement utile lorsque les risques résiduels, après analyse de risques de ré-identification, restent importants
c. Sur le plan technique
- Penser qu’une méthode d’anonymisation peut convenir à tous les cas d’usage : l’anonymisation est généralement réalisée pour un ou plusieurs cas d’usage spécifiques, et ne saurait convenir à tous les cas d’usage. Il est pour cela recommander de mener une analyse d’usage pour s’assurer que les données produites restent utiles pour le besoin cible
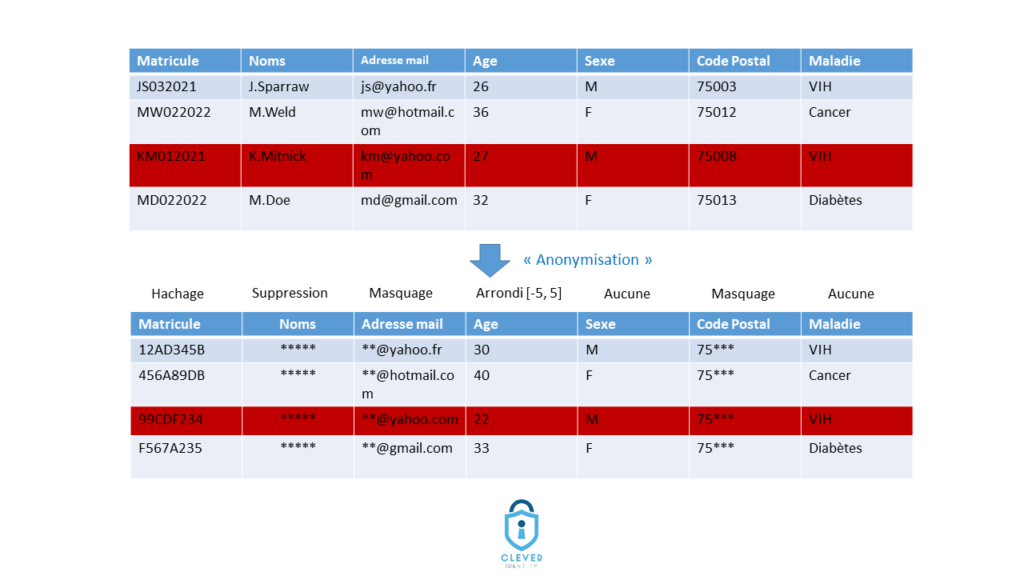
- Confondre anonymisation et pseudonymisation : de loin l’erreur numéro un en matière d’anonymisation. Elle découle principalement d’une mauvaise interprétation de l’expression « irréversible ». En effet, à la différence de la pseudonymisation, l’anonymisation doit être irréversible, et il ne doit pas être possible de retrouver les données d’origine à partir des données anonymisées. Cependant, dans la pratique, des méthodes telles que le hachage ou le chiffrement sont utilisées à tort comme méthodes d’anonymisation, et la notion d’irréversibilité est associée à la difficulté à retrouver la donnée d’origine à partir de la donnée transformée par ces méthodes. Ce qui est une erreur. En effet, bien que ces méthodes soient – dans une certaine mesure – irréversibles, elles ne permettent pas de garantir l’irréversibilité des données de manière globale, car elles n’agissent que sur une partie des données ; le reste des données pouvant permettre une ré-identification par individualisation, corrélation et/ou inférence. La CNIL précise d’ailleurs que le hachage et le chiffrement ne sont pas des méthodes d’anonymisation mais des méthodes de pseudonymisation. Une autre erreur est de penser qu’en multipliant des techniques différentes, on arrive forcément à des données anonymisées, ce qui est faux. Afin de mieux comprendre, considérons les 2 tableaux suivant qui représentent un jeu de données originales (Tableau au-dessus) et sa version dite anonymisée (Tableau en dessous). Plusieurs techniques ont été utilisées pour anonymiser les données (comme on peut l’observer sur le schéma) : hachage, suppression, masquage, arrondi… Cependant, il est toujours possible d’identifier Monsieur K. Mitnick – c’est-à-dire, trouver de quelle maladie il souffre – sur la base des données anonymisées. En effet, en observant les adresses mail transformées, on constate qu’elles sont toutes différentes, ce qui permet d’individualiser toutes les personnes dans cette table et en particulier M. Mitnick. Il est ainsi facile pour un attaquant qui possède l’adresse mail de M. Mitnick, et qui sait qu’il a participé à l’étude, de découvrir qu’il souffre de VIH.
2. Les mesures préconisées :
Afin de garantir une anonymisation conforme, la CNIL recommande une analyse de risques basée sur les 3 critères de ré-identification que sont :
- L’individualisation (Avis du G29) : qui correspond à la possibilité d’isoler une partie ou la totalité des enregistrements identifiant un individu dans l’ensemble de données ;
- La corrélation (Avis du G29) : qui consiste dans la capacité de relier entre elles, au moins deux enregistrements se rapportant à la même personne concernée ou à un groupe de personnes concernées (soit dans la même base de données, soit dans deux bases de données différentes). Si une attaque permet d’établir (par exemple, au moyen d’une analyse de corrélation) que deux enregistrements correspondent à un même groupe d’individus, mais ne permet pas d’isoler des individus au sein de ce groupe, la technique résiste à l’« individualisation », mais non à la corrélation ;
- L’inférence (Avis du G29) : qui est la possibilité de déduire, avec un degré de probabilité élevé, la valeur d’un attribut à partir des valeurs d’un ensemble d’autres attributs
Afin d’y répondre, le G29 identifie des techniques d’anonymisation spécifiques, elles se déclinent selon 2 modèles : la généralisation et la randomisation. La généralisation vise à diluer le niveau d’information contenu dans une donnée (ex : utilisation un code postal plutôt qu’une adresse, une année plutôt qu’une date complète) et la randomisation vise à altérer la véracité des données de manière à empêcher la ré-identification (ex : arrondi de valeurs, permutation de valeurs…).
Comme on a pu l’observer dans l’exemple précédent, il n’est pas suffisant d’utiliser l’un ou l’autre des modèles pour garantir « comme par magie » une anonymisation conforme. Il est nécessaire dans tous les cas, d’évaluer si elles réduisent effectivement les risques de ré-identification que sont l’individualisation, la corrélation et l’inférence. Dans la mesure où le risque résiduel après application de ces techniques reste élevé, il sera alors nécessaire d’implémenter des mesures supplémentaires permettant de réduire ce risque à un niveau acceptable. Par ailleurs, il est recommandé de faire appel à un expert en cas de doute.
3. Conclusion :
L’anonymisation est un traitement permettant une plus grande flexibilité pour le développement de services innovants et l’amélioration de services existants. Cependant, elle est source d’erreurs et d’incompréhensions de la part d’organismes traitant des données à caractère personnel ; cela est principalement due à une méconnaissance des textes régissant l’anonymisation, mais également au niveau d’expertise requise pour mener à bien un processus d’anonymisation. Afin d’éviter ses erreurs, la CNIL recommande de réaliser une analyse de risque de ré-identification basée sur les 3 critères de ré-identification que sont : l’individualisation, la corrélation et l’inférence. Il est par ailleurs recommandé de faire appel à un expert en cas de doute.